
A modern PyTorch implementation of hierarchical deep temporal models for group activity recognition. with 2 LSTM for Person and another to Group capture from person level and group level
Overview • Quick Start • Dataset • Methodology • Results • Architecture
This repository presents a comprehensive implementation and extension of the CVPR 2016 paper "A Hierarchical Deep Temporal Model for Group Activity Recognition". Our approach employs a sophisticated two-stage LSTM architecture that captures both individual player dynamics and collective group behaviors in temporal sequences.
- Enhanced Feature Extraction: ResNet-50 backbone replacing the original AlexNet for superior spatial feature representation
- Comprehensive Ablation Studies: Nine baseline models with detailed performance analysis
- End-to-End Learning: Unified training pipeline for simultaneous individual and group activity recognition
- Superior Performance: Consistent improvements across all baselines compared to original paper results
- Modern Implementation: Complete PyTorch implementation with modular, extensible architecture
- Framework: PyTorch with CUDA support
- Architecture: Hierarchical LSTM with team-aware pooling
- Optimization: AdamW optimizer with learning rate scheduling
- Training Platform: Kaggle GPU (P100/T4) with distributed training support
- Python 3.8+
- CUDA-capable GPU (recommended)
- 16GB+ RAM for full dataset processing
-
Clone Repository
git clone https://github.com/Boules123/A-Hierarchical-Deep-Temporal-Model-for-Group-Activity-Recognition.git cd A-Hierarchical-Deep-Temporal-Model-for-Group-Activity-Recognition -
Install Dependencies
pip install -r requirements.txt
chmod 600 ~/.kaggle/kaggle.json
chmod +x script/download_volleball_dataset.sh
./script/download_volleball_dataset.shThe volleyball dataset comprises 4,830 annotated frames from 55 YouTube videos, providing comprehensive multi-level activity annotations:
-
Group Activities: 8 team-level activity classifications

-
Individual Actions: 9 distinct player action categories

-
Temporal Sequences: 9-frame clips for temporal modeling
| Activity | Instances | Description |
|---|---|---|
| Right Set | 644 | Team positioning for attack |
| Right Spike | 623 | Aggressive attack action |
| Right Pass | 801 | Ball distribution |
| Right WinPoint | 295 | Successful point completion |
| Left WinPoint | 367 | Successful point completion |
| Left Pass | 826 | Ball distribution |
| Left Spike | 642 | Aggressive attack action |
| Left Set | 633 | Team positioning for attack |
| Action | Instances | Frequency |
|---|---|---|
| Standing | 38,696 | 69.8% |
| Moving | 5,121 | 9.2% |
| Waiting | 3,601 | 6.5% |
| Blocking | 2,458 | 4.4% |
| Digging | 2,333 | 4.2% |
| Setting | 1,332 | 2.4% |
| Falling | 1,241 | 2.2% |
| Spiking | 1,216 | 2.2% |
| Jumping | 341 | 0.6% |
- Training: 3,493 frames (24 videos)
- Validation: 1,337 frames (15 videos)
- Testing: 1,337 frames (16 videos)
Video Distribution:
- Train: [1, 3, 6, 7, 10, 13, 15, 16, 18, 22, 23, 31, 32, 36, 38, 39, 40, 41, 42, 48, 50, 52, 53, 54]
- Validation: [0, 2, 8, 12, 17, 19, 24, 26, 27, 28, 30, 33, 46, 49, 51]
- Test: [4, 5, 9, 11, 14, 20, 21, 25, 29, 34, 35, 37, 43, 44, 45, 47]
Check this Repository deep-activity-rec for more information about the volleyball dataset This Repository’s author is a @dr.Mostafa S. Ibrahim
Our comprehensive ablation study evaluates nine distinct baseline architectures, progressively building complexity:
B1: All-Frames Classification B1 is the simplest baseline that classifies the group activity without using any temporal modeling. It uses a ResNet-50 backbone fine-tuned on the volleyball dataset to predict one of the 8 group activities. This model relies only on appearance and spatial layout from a Nine frames. Its main limitation is confusion between left vs. right actions due to lack of motion/temporal context.
- Keywords: ResNet-50 backbone, Direct group activity classification, No player tracking needed, Left/Right confusion
B3: Person-Centric Features B3 improves over the all-9 frames baseline by focusing on individual players instead of the whole image. Each player crop is passed through ResNet-50 to extract features(2048 features), which are then pooled globally across all players (MAX Pool). This captures the presence and distribution of actions among individuals rather than only global context. However, it does not yet model temporal dynamics and also loses team-specific structure during pooling. It serves as a bridge baseline between global-only and temporal/person-aware models.
- keywords: ResNet-50 on individual player crops, Per-player feature extraction, Global pooling across players (MAX Pool)
B4: Temporal Image Features B4 introduces temporal modeling but still works at the global image level. Instead of relying on a frames, a sequence of 9 frames is used, and global ResNet-50 features are extracted from each frame. These features are then fed into an LSTM to capture short-term temporal dynamics across frames. This allows the model to learn motion cues and sequential context, but it still ignores individual player actions. Thus, B4 improves recognition of dynamic group activities, but struggles when fine-grained player behaviors matter.
- keywords: ResNet-50 + LSTM, Global image features over time, 9-frame temporal sequence, Good for dynamic group actions
B5: Temporal Person Features B5 focuses on individual players over time instead of just global frames. Each player crop is passed through ResNet-50 for feature extraction, and then an LSTM is applied per player to capture their temporal dynamics. The player-level temporal features are then pooled globally across all players to represent the team. This design better models how individual actions evolve over time, but still loses team-specific structure due to global pooling. It’s more powerful than B3 and B4 but not as strong as hierarchical or team-aware approaches.
- keywords: ResNet-50 + LSTM per player, Per-player temporal modeling, Global pooling across all players, Captures individual action dynamics
B6: Hierarchical without Stage 1 B6 introduces a group-level temporal model but skips the person-level LSTM stage. Instead of modeling each player individually, it directly feeds global pooled features into a group-level LSTM. This lets the model capture overall team dynamics across time, but it ignores fine-grained individual temporal behavior. While simpler and faster, it sacrifices some detail compared to per-player modeling, yet still shows strong performance. It demonstrates the value of group-level temporal aggregation even without individual action modeling.
- keywords: Group-level temporal modeling, No person-level LSTM, Global pooled features → Group LSTM, Captures team dynamics over time
B7: Two-Stage with Global Pooling B7 brings back the two-stage design: a person-level LSTM first, followed by a group-level LSTM. Each player’s temporal features are extracted with a person LSTM, then globally pooled across all players before passing into the group LSTM. This captures both individual dynamics and overall team evolution in time, giving a stronger model than B5 or B6. However, because of global pooling, it loses team-specific structure (Left vs Right), which limits its ability to separate symmetric actions. It represents an important step toward the final team-aware hierarchical model.
- keywords: Two-stage hierarchical design, Person LSTM → Global pooling → Group LSTM, Captures individual + group dynamics
B8: Team-Aware Hierarchical Model B8 is the most advanced baseline, designed to fully capture hierarchical, temporal, and team-level structures in group activities. It builds on the two-stage architecture of B7 but separates players by team (Left vs Right) before aggregation. At the first stage, each player is modeled with a person-level LSTM to capture their individual temporal dynamics. At the second stage, features are pooled separately for each team, ensuring the model keeps track of team identities and structures. These team-level features are then passed to a group-level LSTM, which models how the two teams interact over time. By explicitly preserving team separation, B8 solves the left/right confusion problem of earlier baselines. It achieves the best accuracy among all baselines, as it balances individual modeling, temporal context, and team structure awareness.
- keywords: Two-stage LSTM: Person → Team → Group, Separates Left vs Right team features
Our team-independent pooling mechanism preserves critical spatial relationships:
- Players 1-6: Left Team features
- Players 7-12: Right Team features
- Concatenated team representations maintain positional context
| Baseline | Accuracy | F1 Score |
|---|---|---|
| B1: 9 Frame | 72.79% | 72.84% |
| B3: Person Features | 81.11% | 80.99% |
| B4: Temporal Image | 77.56% | 77.39% |
| B5: Temporal Person | 78.61% | 78.70% |
| B6: Hierarchical (No Stage 1) | 83.40% | 83.28% |
| B7: Two-Stage Global | 86.84% | 86.83% |
| B8: Team-Aware Hierarchical | 90.50% | 90.48% |

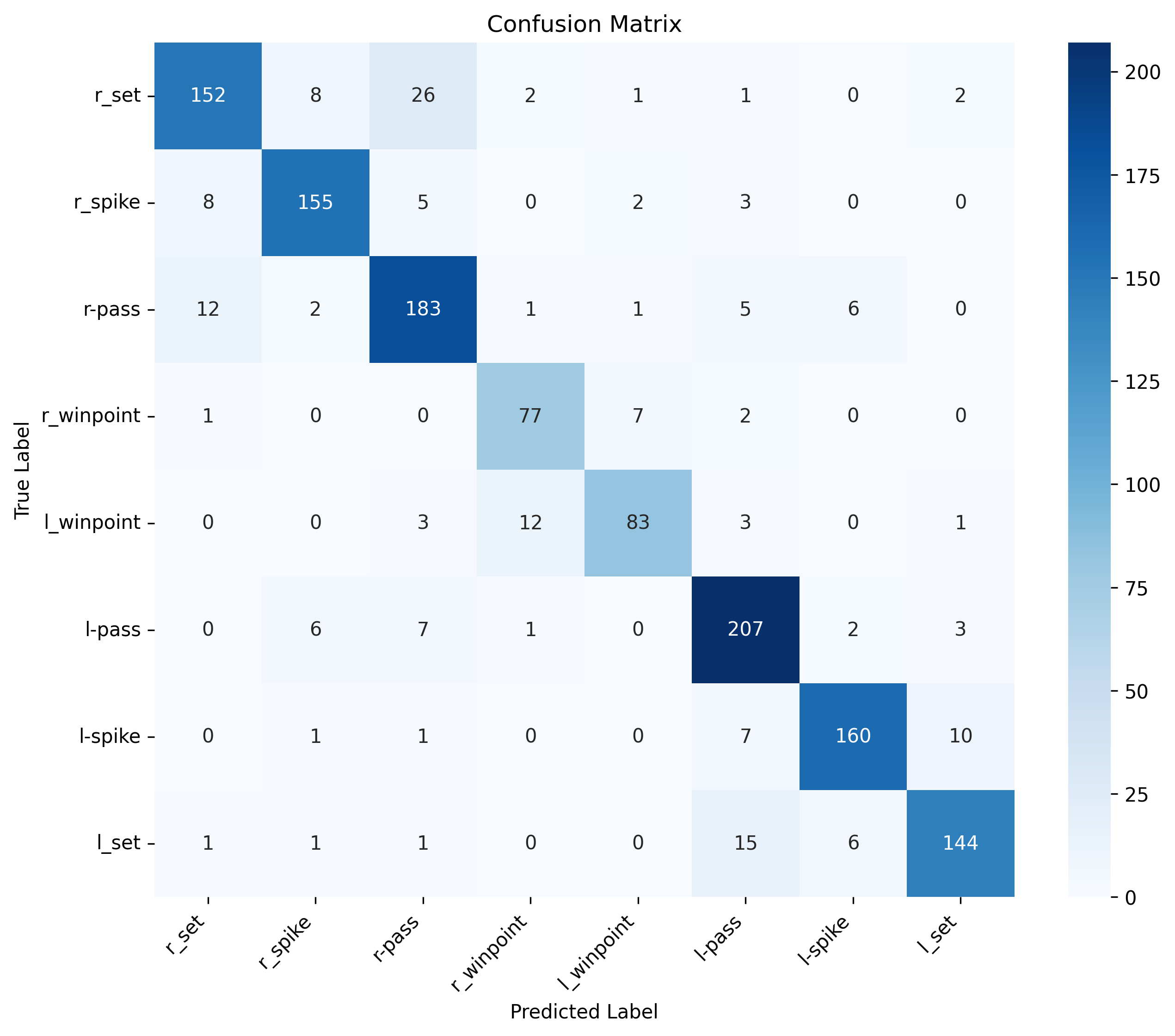
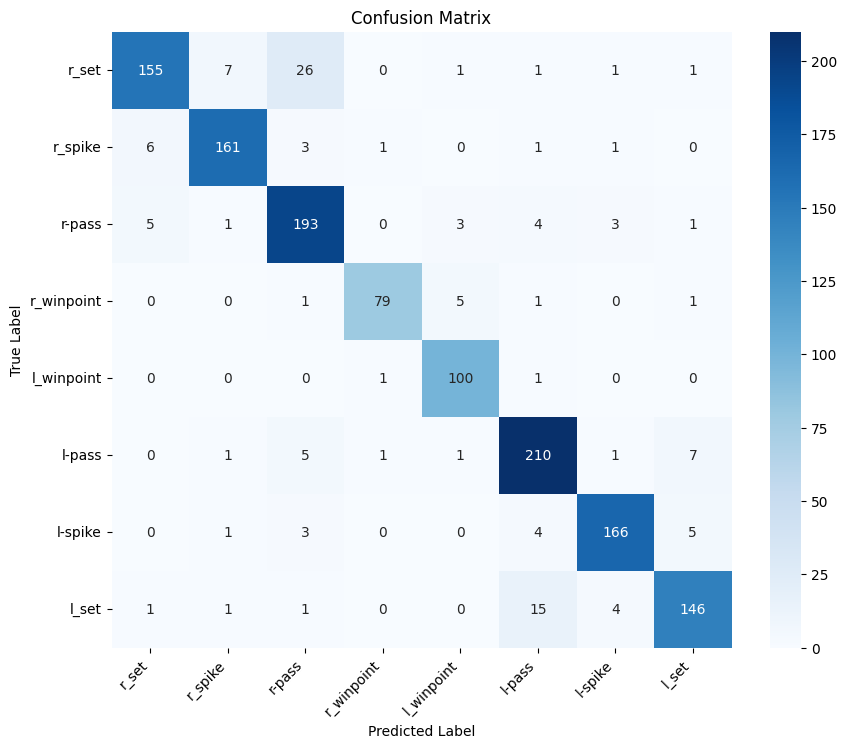
The progression from global pooling (B5-B6) to team-aware pooling (B7-B8) demonstrates significant improvement in distinguishing between team-specific actions:
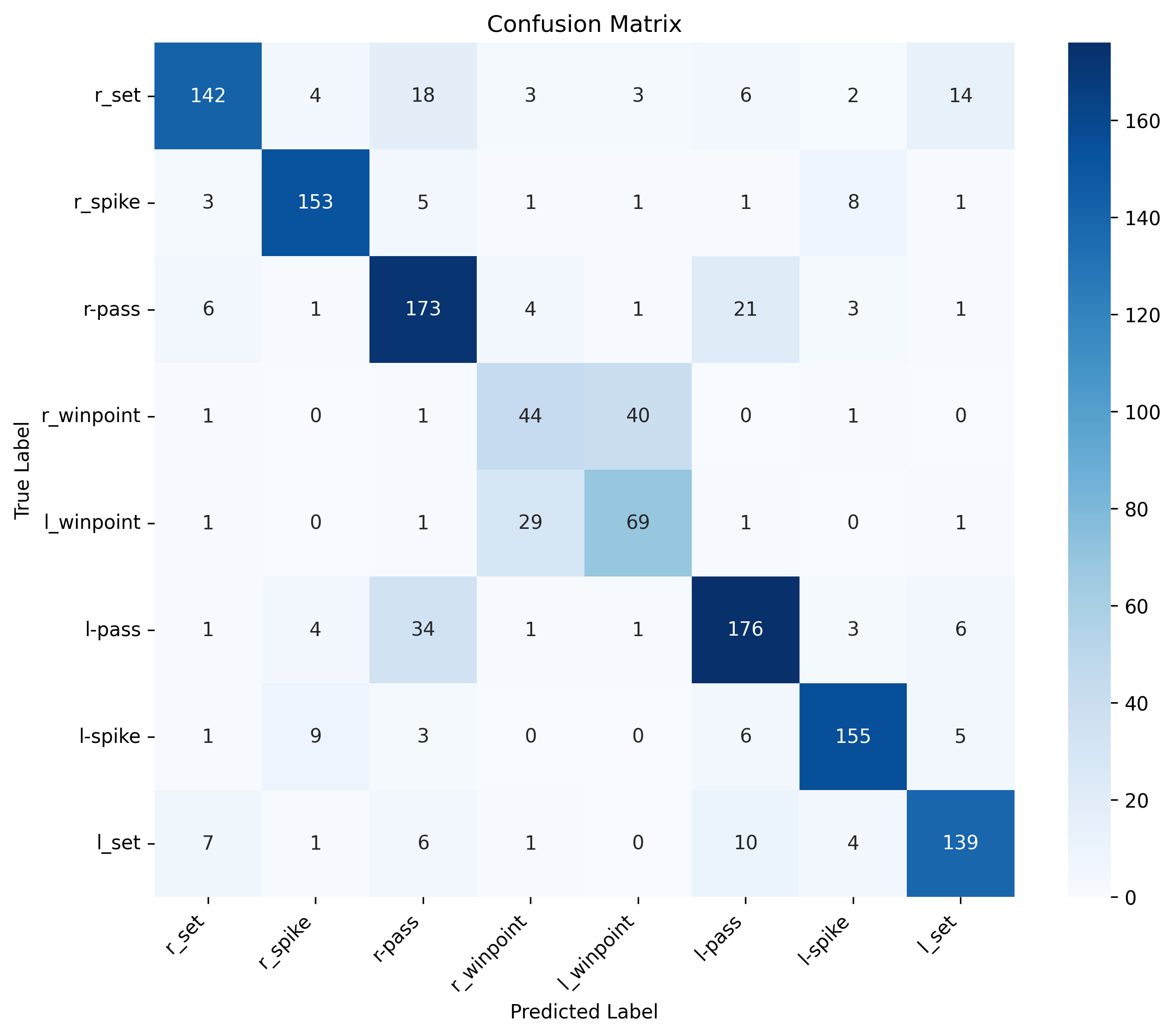
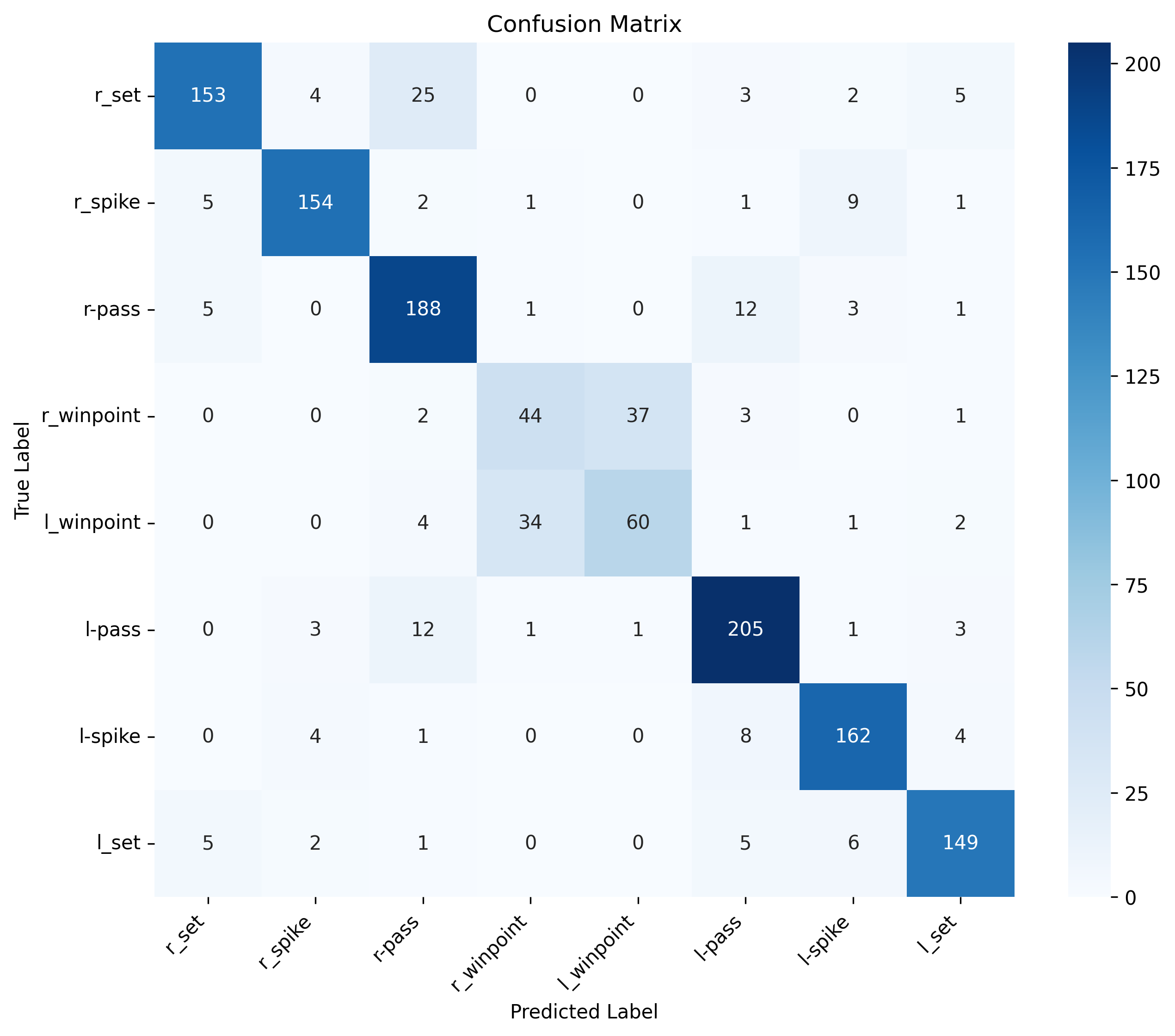
Common Confusions (Global Pooling):
- Right winpoint ↔ Left winpoint
- Right pass ↔ Left pass
- Right set ↔ Left set
- Right spike ↔ Left spike
Resolution (Team-Aware Pooling): Team-independent processing preserves geometric relationships, enabling better discrimination between laterally symmetric actions.
The model architecture is designed for temporal scene classification in multi-person environments, specifically targeting scenarios with 12 individuals organized into two teams of 6 players each. This section provides a detailed description of the components and processing stages that enable hierarchical understanding from individual behavior to group dynamics.
The model employs a two-stage approach:
- Person-Level Feature Processing: Individual player features are extracted and processed temporally using a pre-trained backbone and LSTM from an existing person classifier.
- Group-Level Temporal Integration: Team-level features are aggregated and processed using a dedicated LSTM to classify scene activities into 8 categories.
The person-level component leverages a pre-trained PersonTempClassifier to extract and process individual player features from input video sequences. This component handles the foundational understanding of individual human behavior and temporal patterns.
-
Feature Extraction Backbone: A pre-trained convolutional neural network backbone (inherited from the person classifier) extracts spatial visual features from individual player crops across video frames. This component has been trained on person classification tasks and provides robust feature representations for human appearance and pose.
-
Person-Level Temporal Modeling: An LSTM network processes sequential features for each individual player, capturing temporal dependencies in their movements and actions. This LSTM has been pre-trained to understand individual human behavioral patterns over time.
-
Feature Fusion: The model concatenates original backbone features with LSTM temporal features, creating enriched representations that combine both spatial appearance information and temporal behavioral patterns for each player.
The input video sequences are reshaped to process individual frames through the feature extraction backbone. Each player's features are then processed through the person-level LSTM to generate temporal representations. These features are combined to create comprehensive per-player feature vectors that encode both visual appearance and behavioral dynamics.
Input: Player Crops (NxTxCxHxW)
↓
ResNet-50 Feature Extraction (2048-D)
↓
Individual LSTM (Hidden: 512)
↓
FC Layers → Individual Activity Classes (9)
The SceneTempClassifier_B8 extends the person-level processing to incorporate team dynamics and scene-level understanding. This component focuses on learning group interactions and temporal scene patterns.
-
Shared Backbone and Person LSTM: The ResNet backbone and person LSTM from the
PersonTempClassifierare incorporated with frozen parameters to leverage pre-trained individual understanding while preventing degradation of learned person-level features. -
Team-Aware Feature Aggregation:
- Individual player features are organized into two distinct teams (players 1-6 for Team A and players 7-12 for Team B).
- An adaptive max-pooling layer aggregates player features within each team, capturing the most salient characteristics of each team's collective state.
- Features from both teams are concatenated to form comprehensive scene representations.
-
Group-Level Temporal Modeling: A dedicated LSTM processes the concatenated team-level features over temporal sequences, learning to capture team interactions, competitive dynamics, and scene evolution patterns. This LSTM has trainable parameters to learn scene-specific temporal patterns.
-
Scene Classification Head: A series of fully connected layers with batch normalization, ReLU activation, and dropout regularization map the group LSTM outputs to final scene activity classifications across 8 target classes.
After person-level processing, player features are reorganized by team structure. Team-level aggregation reduces individual player features to team representations while preserving the most important collective information. The group LSTM processes these team features temporally, and the final time step output is classified through the dense classification layers.
Individual Features
↓
Team Grouping: [Players 1-6] | [Players 7-12]
↓
Adaptive Max Pooling per Team
↓
Feature Concatenation (5120-D)
↓
Group LSTM (Hidden: 512)
↓
FC Layers → Group Activity Classes (8)
- GPU: NVIDIA P100 (16GB) or T4 (15GB)
- Memory: 16GB+ system RAM
- Storage: 50GB+ for dataset and models
- Optimizer: AdamW (lr=1e-4, weight_decay=1e-2)
- Scheduler: ReduceLROnPlateau
- Batch Size: 4 (memory optimized)
- Epochs: 50
- Regularization: Dropout (0.5), Label Smoothing (0.1)
If you use this work in your research, please cite:
@article{GroupActivityRecognition2025,
title ={Modern Implementation of Hierarchical Deep Temporal Models for Group Activity Recognition},
author ={Boules Ashraf},
journal ={GitHub Repository},
year ={2025},
url ={(https://github.com/Boules123/A-Hierarchical-Deep-Temporal-Model-for-Group-Activity-Recognition.git)}
}
@inproceedings{msibrahiCVPR16deepactivity,
author = {Mostafa S. Ibrahim, Srikanth Muralidharan, Zhiwei Deng, Arash Vahdat, Greg Mori},
title = {A Hierarchical Deep Temporal Model for Group Activity Recognition.},
booktitle = {2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}- Original paper authors for the foundational volleyball dataset
- Kaggle for computational resources and model hosting
- PyTorch community for framework support
This project is licensed under the BSD-2-Clause License - see the LICENSE file for details.