Search: index <dl>s as sections and remove Sphinx domain logic #10128
Conversation
|
@stsewd I wasn't able to find any real-life Sphinx HTML output that I was sure would match the intention of this change. The implementation seems fine and solid, but I just wonder which Edit: Maybe this is it? https://docs.readthedocs.io/en/stable/glossary.html |
http domains https://docs.readthedocs.io/en/stable/api/v3.html#get--api-v3-projects-, and autodoc output https://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-automodule |
|
https://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-automodule is kind of an interesting case, it has several aliases, we may do some research if that's the standard way of doing that, and see how we can handle those cases, but also, something that can be done in another PR. |
|
Great! Thanks! I'll brew up some test cases based on this 👍 |
|
@stsewd I added httpdomain and autodoc test data. Could you give it a review again? The most important part is to understand if the JSON data pertaining sections is how you'd expect from the HTML. |
…neric-html-parser-dls-remove-sphinx-domain
a15e620 to
562d18b
Compare
As you can see, a lot of changes went in 😞 Kudos to your objection to the removal of That also meant that parts of the approach wasn't accurate... I found out that "pre-removing" content in Finally, I split everything into a new |
…neric-html-parser-dls-remove-sphinx-domain
There was a problem hiding this comment.
I think we can avoid assigning the random UUID. Everything else looks good.
There is also one thing we haven't taken into consideration, this is domain titles are currently indexed using the simple analyzer
readthedocs.org/readthedocs/search/documents.py
Lines 119 to 123 in 32ffebe
And sections use the default (standard) analyzer (https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html). We are using the simple analyzer because mostly of the domains are in the form of foo.bar (and the simple analyzer splits that into foo and bar, and the default analyzer makes it a whole word).
I think I'm fine with that (maybe we should invest in partial matches more, like experiment with https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-edgengram-tokenizer.html?), but maybe @ericholscher has some opinions here.
I don't have a great sense for the trade-offs here. I do know we had users who would complain because they couldn't search for things that include periods and get the good results. I think as long as we have a way to ensure the search query is mapped reasonably onto the results, it should be fine. If we index |
Good question, so analyzers are applied to both, the indexed content and the query (by default the same analyzer used for index is used for search). So searching for |
|
Yep, confirmed, the only thing is that the highlight would be broken into three matches.
(this was searching |
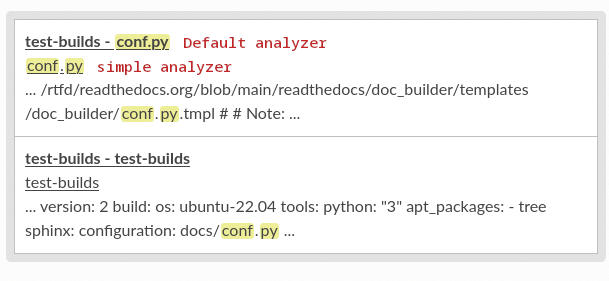
|
Awesome! Thanks for all the accurate and helpful feedback. @stsewd I guess that #10184 will require a bit similar research to what you just did, so if there is anything else regarding search indexing and search results, we could take it up there. Do we need to open another issue about the next pieces to remove? I'm guessing it'd be nice to only have the generic parser left if possible? |
Oh heh, now I got a bit confused - are you waiting for anything else regarding analyzer stuff? Or is that referring to previous analysis? It seems to be concluding that the search analyzer works, it's only the highlighting that was different? |
With this change we are changing from using the simple analyzer to using the default analyzer for sphinx domains (description lists now). The simple analyzer will break |
….com:readthedocs/readthedocs.org into generic-html-parser-dls-remove-sphinx-domain
|
@stsewd added on |
|
I think it's probably worth a little more discussion before changing the analyzer, I'm fine merging this without the analyzer changes. Changing the analyzer will require a re-index. |
This reverts commit ffca7ad.
Check 👍 Reverted it. So this should be done now, I mentioned the analyzer in #10184 for now, but we can also open a separate issue. |
WIP - need to test this, just want to know that this is what you had in mind. I'll test and make it ready for review then. CC: @humitos @stsewd
Fixes: #9571