OpenCodeReview is an advanced AI-powered source code review tool and vulnerability management system that leverages NVIDIA NeMo Agent Toolkit (NAT) for intelligent security analysis and code assessment.
Transform traditional code review processes with intelligent AI automation, providing enterprise-grade security analysis without requiring AI expertise from development teams.
Core AI Engine: NVIDIA NeMo Agent Toolkit orchestrates sophisticated AI workflows through:
- Code Acquisition: Automated source code retrieval and processing
- Security Analysis: AI-powered OWASP Top 10 2021 vulnerability assessment
- Finding Management: Automated vulnerability record creation and classification
- QA Validation: AI-powered false positive detection and confidence scoring
- Cloud LLMs: OpenAI GPT models, NVIDIA NIM API access
- Local Deployment: Ollama integration for on-premises privacy
- Dynamic Switching: Runtime provider configuration without code changes
- Selective Review: Choose specific OWASP categories for targeted analysis
- AI QA Review: Automated false positive detection with confidence scoring
- Real-time Updates: WebSocket-powered live analysis progress
- Multi-Format Export: Comprehensive reporting in various formats
- ✅ Zero AI Expertise Required: Expert security analysis prompts pre-configured and embedded
- ✅ Enterprise-Ready: Modern NAT architecture with improved reliability and performance
- ✅ Maximum Flexibility: Multi-provider LLM support (OpenAI, NVIDIA, Local Ollama)
- ✅ Enhanced Privacy: Complete local deployment option with Ollama integration
- ✅ Future-Proof Design: Built on NVIDIA's latest agent framework technology
- ✅ Intelligent Validation: AI-powered QA review reduces false positives significantly
- ✅ Cost Optimization: Choose between premium cloud models or free local alternatives
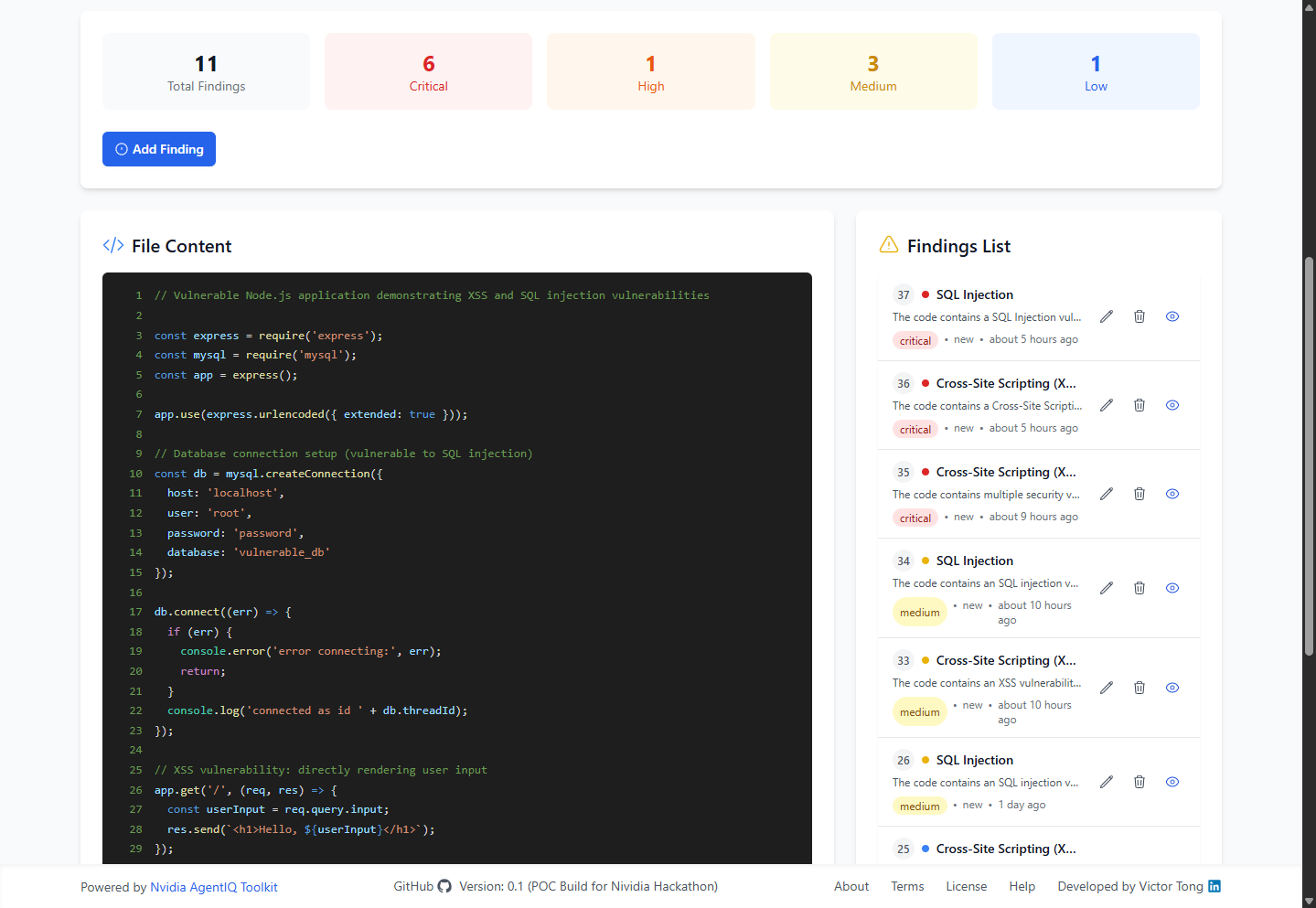
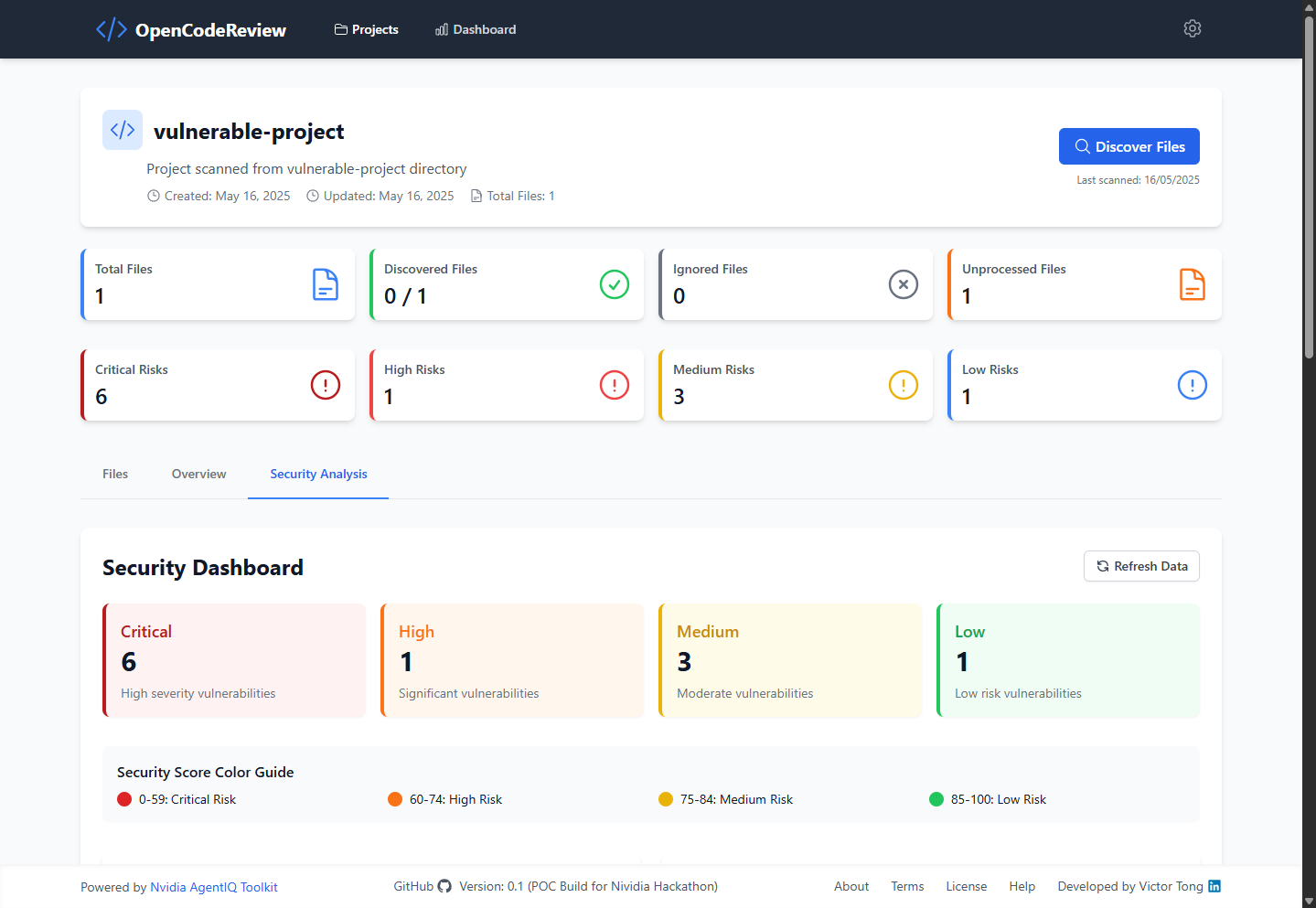
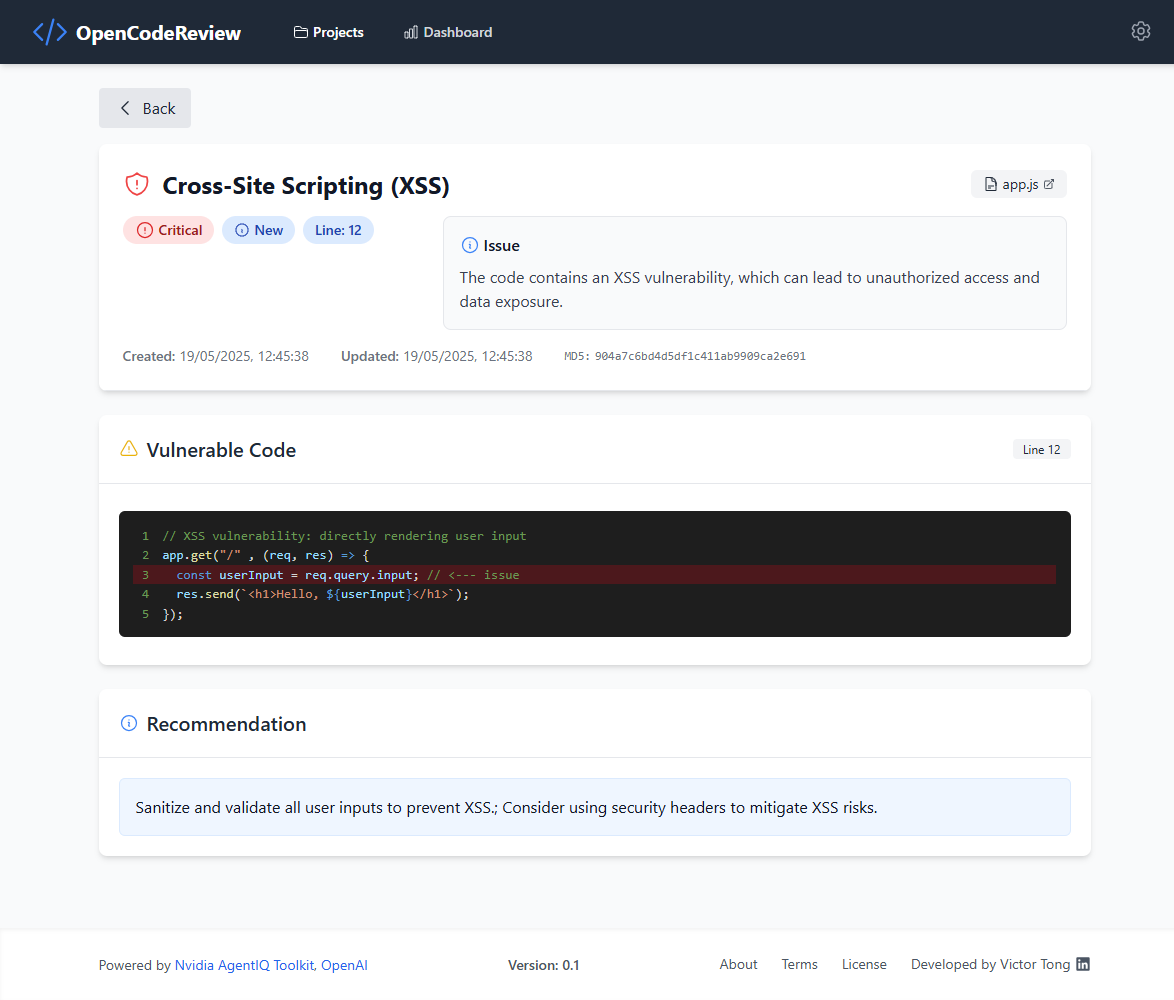
The OpenCodeReview application utilizes a modern, containerized architecture with separate components for frontend, backend, AI processing, and data storage.
- Frontend: React 19 with TypeScript - Modern interactive user interface with Redux Toolkit and Tailwind CSS
- Backend: Node.js with Express & TypeScript - Handles API requests, business logic, and Sequelize ORM
- Database: PostgreSQL with PgVector extension - Stores application data with vector search capabilities
- AI Engine: NVIDIA NeMo Agent Toolkit (NAT) - Advanced AI orchestration and code analysis engine
- LLM Providers: Multi-provider support (OpenAI, NVIDIA, Ollama) - Flexible AI model integration
- MCP Server: Model Context Protocol server - Enhanced AI communication layer
- Deployment: Docker Compose - Containerized microservices architecture with isolated networks
All components run in isolated Docker containers with secure networking and service isolation.
┌─────────────────────────────────────────────────────────────────────────┐
│ OpenCodeReview Architecture │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ HTTP/WS ┌─────────────┐ │
│ │ Frontend │◄─────────────►│ Backend │ │
│ │ (React) │ Port 5174 │ (Node.js/ │ │
│ │ Vite+TS │ │ Express) │ │
│ └─────────────┘ └─────────────┘ │
│ │ │
│ │ HTTP │
│ ▼ │
│ ┌─────────────┐ │
│ ┌─────────────┐ HTTP │ Database │ │
│ │ MCP Server │◄───────────┤ PostgreSQL │ │
│ │ (Python) │Port 8002 │ + PgVector │ │
│ │ Port 8002 │ └─────────────┘ │
│ └─────────────┘ ▲ │
│ │ │ │
│ │ Protocol │ SQL/ORM │
│ ▼ │ │
│ ┌─────────────────────────────────────────────────────────────────────┤
│ │ NeMo Agent Toolkit (NAT) │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ │ FastAPI │ │ Agents │ │ Tools │ │
│ │ │ Server │ │ Engine │ │ Functions │ │
│ │ │ Port 8000 │ │ │ │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ │ NAT UI │ │ Multi-LLM │ │ Code Review │ │
│ │ │ (React) │ │ Providers │ │ Agents │ │
│ │ │ Port 3000 │ │ │ │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │
│ └─────────────────────────────────────────────────────────────────────┤
│ │
│ External Connections: │
│ • OpenAI API (gpt-4o, gpt-4o-mini) │
│ • NVIDIA NIM API (llama models) │
│ • Local Ollama Server (when configured) │
│ │
└─────────────────────────────────────────────────────────────────────────┘
Data Flow:
1. User uploads code → Frontend → Backend → Database
2. User triggers analysis → Backend → NAT via HTTP
3. NAT processes with LLM → Creates findings → Database
4. Real-time updates → WebSocket → Frontend
5. QA Review → NAT → Updates findings status
- Frontend (React): Port 5174 - Main user interface
- Backend API & WebSockets: Port 8001 - REST API and real-time updates
- NeMo Agent Toolkit: Port 8000 - AI processing and analysis engine
- NAT UI: Port 3000 - AI operations visualization interface
- MCP Server: Port 8002 - Model Context Protocol communication
- Database: Port 5435 - PostgreSQL with PgVector
.
├── .env_example # Environment template
├── .gitignore # Git ignore rules
├── 00-setup_nemo_agent_toolkit.sh # NeMo Agent Toolkit setup script
├── docker-compose.yml # Main Docker configuration
├── docker-compose_nemo_agent_toolkit.yml # NeMo Agent Toolkit Docker Compose
├── Dockerfile-nemo_agent_toolkit # NeMo Agent Toolkit Dockerfile
├── package.json # Root package configuration
├── README.md # Project documentation
├── restart.sh # Application restart script
├── run_example.sh # Example run script
├── run_migrations.sh # Database initialization script
├── run_opencodereview.sh # OpenCodeReview run script
├── start_open-code-review.sh # Start all services
├── stop_open-code-review.sh # Stop all services
├── backend/ # Node.js backend
│ ├── .gitignore # Backend git ignore
│ ├── .sequelizerc # Sequelize config
│ ├── Dockerfile
│ ├── jest.config.js # Jest test configuration
│ ├── package.json # Backend dependencies
│ ├── tsconfig.json # TypeScript configuration
│ ├── config/ # Configuration files
│ ├── models/ # Database models
│ ├── projects/ # Project data
│ └── src/ # Source code
│ ├── controllers/ # API route handlers
│ ├── routes/ # Express route definitions
│ ├── services/ # Business logic and integrations
│ │ └── natClient.ts # NeMo Agent Toolkit client
│ ├── models/ # Sequelize database models
│ └── migrations/ # Database schema migrations
├── frontend/ # React.js frontend
│ ├── .gitignore # Frontend git ignore
│ ├── .stylelintrc.json # Stylelint configuration
│ ├── API_DOCUMENTATION.md # API documentation
│ ├── Dockerfile
│ ├── README.md # Frontend documentation
│ ├── eslint.config.js # ESLint configuration
│ ├── index.html # Main HTML file
│ ├── package.json # Frontend dependencies
│ ├── postcss.config.cjs # PostCSS configuration
│ ├── postcss.config.js # PostCSS configuration (JS)
│ ├── restart-app.sh # Frontend restart script
│ ├── tailwind.config.cjs # Tailwind CSS configuration
│ ├── tailwind.config.js # Tailwind CSS configuration (JS)
│ ├── tsconfig.app.json # App TypeScript configuration
│ ├── tsconfig.json # TypeScript configuration
│ ├── tsconfig.node.json # Node TypeScript configuration
│ ├── vite.config.ts # Vite configuration
│ ├── public/ # Static assets
│ ├── scripts/ # Build scripts
│ └── src/ # Source code
│ ├── components/ # Reusable React components
│ ├── pages/ # Route-based page components
│ ├── features/ # Redux Toolkit slices
│ ├── services/ # API client and WebSocket handling
│ ├── hooks/ # Custom React hooks
│ └── utils/ # Utility functions
├── my-agents/ # NeMo Agent Toolkit custom agents
│ └── open_code_review/ # OpenCodeReview agent implementation
│ ├── pyproject.toml # Python project configuration
│ └── src/open_code_review/ # Agent source code
│ ├── configs/ # Agent configuration files
│ │ └── config.yml # Multi-provider LLM configuration
│ ├── tools/ # Custom agent tools
│ └── workflows/ # Agent workflow definitions
├── mcp_server/ # Model Context Protocol server
│ ├── Dockerfile # MCP server container
│ ├── requirements.txt # Python dependencies
│ └── src/ # MCP server implementation
└── projects/ # Project uploads folder
├── owasp-sample-code/ # OWASP sample project
└── vulnerable-project/ # Sample vulnerable project
OpenCodeReview supports multi-provider LLM architecture with flexible configuration through environment variables. The system automatically selects the appropriate LLM client based on your chosen provider.
Configure your preferred LLM provider in the .env file:
# Choose provider: openai, nvidia, or ollama
LLM_PROVIDER=openai
# Provider-specific settings (configure based on your choice)
LLM_MAX_TOKENS=4096
LLM_TEMPERATURE=0.0✅ Best Choice: Reliable, well-tested, and supports all features
LLM_PROVIDER=openai
OPENAI_API_KEY=your_openai_api_key
OPENAI_MODEL=gpt-4o-mini
OPENAI_BASE_URL=https://api.openai.com/v1Recommended Models:
gpt-4o- Best quality, higher costgpt-4o-mini- Good balance of quality and cost ⭐ Defaultgpt-4-turbo- Alternative premium option
✅ Enterprise: Access to latest NVIDIA-hosted models
LLM_PROVIDER=nvidia
NVIDIA_API_KEY=your_nvidia_api_key
NVIDIA_MODEL=meta/llama-3.1-8b-instruct
NVIDIA_BASE_URL=https://integrate.api.nvidia.com/v1Recommended Models:
meta/llama-3.1-8b-instruct- Fast, function calling supported ⭐ Recommendedmeta/llama-3.1-70b-instruct- Higher quality, slowermicrosoft/phi-3-medium-4k-instruct- Efficient alternative
- Ollama Server: Install and run Ollama on your network
- Function Calling Support:
⚠️ Critical - Model must support tools/function calling - Sufficient Resources: 8GB+ VRAM recommended for quality models
LLM_PROVIDER=ollama
OLLAMA_URL=http://192.168.1.100 # Your Ollama server IP
OLLAMA_PORT=11434
OLLAMA_MODEL=your_model_name
OLLAMA_API_KEY=EMPTY✅ Verified Compatible Models:
llama3.1:8b- Good balance of performance and resourcesqwen2.5:7b- Excellent code analysis capabilitiescodestral:22b- Specialized for code review (requires more resources)
❌ Known Incompatible Models:
gemma3:4b- Does not support function callingphi3:3.8b- Limited tool support- Most older or smaller models
Before configuring, test if your model supports function calling:
curl -X POST http://your.ollama.host:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "your_model_name",
"messages": [{"role": "user", "content": "Hello"}],
"tools": [{"type": "function", "function": {"name": "test"}}]
}'If you receive a 400 error mentioning "does not support tools", the model is incompatible.
To switch providers, simply update the LLM_PROVIDER environment variable and restart the NAT service:
# Update .env file
LLM_PROVIDER=your_new_provider
# Restart NAT service only
docker compose restart nvidia-nat| Provider | Setup Complexity | Cost | Performance | Privacy | Function Calling |
|---|---|---|---|---|---|
| OpenAI | Easy | Paid | High | Cloud | ✅ Full Support |
| NVIDIA | Medium | Paid | High | Cloud | ✅ Full Support |
| Ollama | Hard | Free | Variable | Local |
- Getting Started: OpenAI
gpt-4o-mini - Enterprise/Production: NVIDIA NIM
meta/llama-3.1-8b-instruct - Privacy/Offline: Ollama
llama3.1:8b(with proper hardware) - Best Quality: OpenAI
gpt-4oor NVIDIAmeta/llama-3.1-70b-instruct
- Docker and Docker Compose installed
- Minimum 8GB RAM and 4 CPU cores recommended
- API keys configured in
.envfile (see LLM Configuration section) - Docker image
nvcr.io/nvidia/base/ubuntuaccess (NVIDIA account required) - Internet connectivity for pulling Docker images and AI model access
-
Clone Repository:
git clone https://github.com/victortong-git/open-code-review.git cd open-code-review/ -
Configure Environment:
cp .env_example .env # Edit .env file with your preferred LLM provider and API keys -
Setup NeMo Agent Toolkit:
./00-setup_nemo_agent_toolkit.sh
This builds the NeMo Agent Toolkit Docker container with all dependencies.
-
Choose Your LLM Provider: Edit
.envfile to configure your preferred provider:For OpenAI (Recommended for beginners):
LLM_PROVIDER=openai OPENAI_API_KEY=your_openai_api_key OPENAI_MODEL=gpt-4o-mini
For NVIDIA NIM:
LLM_PROVIDER=nvidia NVIDIA_API_KEY=your_nvidia_api_key NVIDIA_MODEL=meta/llama-3.1-8b-instruct
For Local Ollama:
LLM_PROVIDER=ollama OLLAMA_URL=http://your.ollama.host OLLAMA_MODEL=your_model_name
⚠️ Note: Ensure your chosen model supports function calling (required by NAT) -
Start Application Services:
./start_open-code-review.sh
This starts all containerized services: frontend, backend, database, and NeMo Agent Toolkit.
-
Initialize Database:
./run_migrations.sh
Creates database schema and loads initial data.
-
Access Application:
- Frontend:
http://localhost:5174(Main application interface) - Backend API:
http://localhost:8001(REST API and WebSocket) - NAT UI:
http://localhost:3000(NeMo Agent Toolkit management) - MCP Server:
http://localhost:8002(Model Context Protocol)
- Frontend:
After setup, verify the installation by:
- Checking all services are running:
docker compose ps - Testing AI functionality on a sample file
- Monitoring logs for any errors:
docker compose logs -f
Error: "model does not support tools" (status code: 400)
Cause: Your chosen LLM model doesn't support function calling required by NeMo Agent Toolkit.
Solutions:
- Quick Fix: Switch to OpenAI provider:
# Update .env file LLM_PROVIDER=openai OPENAI_API_KEY=your_key # Restart NAT service docker compose restart nvidia-nat
- Ollama Users: Use compatible models like
llama3.1:8binstead ofgemma3:4b - Test Model: Use the curl command in LLM Configuration section to verify compatibility
Error: Containers failing to start or exiting immediately
Diagnosis:
# Check service status
docker compose ps
# View specific service logs
docker compose logs nvidia-nat
docker compose logs backend
docker compose logs frontendCommon Causes:
- Missing Environment Variables: Ensure
.envfile is properly configured - Port Conflicts: Check if ports 5174, 8001, 8000, 3000, 8002, 5435 are available
- Docker Image Issues: Try rebuilding:
docker compose build --no-cache
Symptoms: Analysis never completes or returns errors
Solutions:
-
Check NAT Service:
docker compose logs nvidia-nat curl http://localhost:8000/health # Should return OK -
Verify LLM Provider Connection:
# Test API key (OpenAI example) curl -H "Authorization: Bearer $OPENAI_API_KEY" \ https://api.openai.com/v1/models
-
Increase Timeouts: Edit backend configuration if needed
-
Check Rate Limits: NVIDIA and OpenAI have rate limiting
Error: Backend can't connect to PostgreSQL
Solutions:
# Check database service
docker compose logs postgres
# Test database connection
docker compose exec postgres psql -U postgres -d opencodereview -c "SELECT 1;"
# Rebuild database if needed
docker compose down -v
docker compose up -d postgres
./run_migrations.shSymptoms: API calls failing, empty data
Solutions:
- Check Backend Status:
curl http://localhost:8001/api/health - CORS Issues: Ensure backend CORS is configured for localhost:5174
- Network Issues: Verify containers are on same Docker network
Error: Can't connect to Ollama server
Solutions:
- Network Access: Ensure Ollama host is reachable:
ping your.ollama.host - Firewall: Check if port 11434 is open
- Model Availability: Verify model is pulled:
ollama list - URL Format: Use
http://prefix in OLLAMA_URL
Enable verbose logging for detailed troubleshooting:
# Add to .env file
DEBUG=true
LOG_LEVEL=debug
# Restart services
docker compose restart- Check Logs: Always start with
docker compose logs -f - Service Health: Use health check endpoints where available
- Community Support: Report issues on GitHub repository
- Documentation: Refer to component-specific documentation in respective directories
- Resource Allocation: Ensure sufficient RAM (8GB+) and CPU (4+ cores)
- Model Selection: Smaller models (gpt-4o-mini) for faster responses
- Local Setup: Use local Ollama for better performance and privacy
- Caching: Clear Docker cache periodically:
docker system prune

OpenCodeReview has successfully migrated from AIQ Toolkit → NeMo Agent Toolkit (NAT).
✅ Migration Status: COMPLETE - All users should use the new NAT-based installation process.
./00-setup_aiqtoolkit.sh→ Use:./00-setup_nemo_agent_toolkit.shdocker-compose_aiqtoolkit.yml→ Use:docker-compose_nemo_agent_toolkit.ymlDockerfile-aiqtoolkit→ Use:Dockerfile-nemo_agent_toolkitaiqtoolkit-ui/directory → Replaced by: Native NAT UI (Port 3000)
- Environment Variables:
- Old:
AIQ_*variables → New:LLM_PROVIDER,NVIDIA_*,OPENAI_*,OLLAMA_*
- Old:
- Service Names:
- Old:
aiqtoolkitservice → New:nvidia-natservice
- Old:
- API Endpoints:
- Old:
aiqClient.ts→ New:natClient.ts
- Old:
- Function Calling Requirement:
- Critical: LLM models MUST support function calling (not all Ollama models supported)
- Production Ready: Enterprise-grade NAT architecture with enhanced reliability
- Multi-Platform Tested: CentOS 9, Ubuntu 20.04+, macOS (Docker Desktop)
- Container Orchestration: Full Docker Compose with service isolation and health checks
- Cloud Providers: Internet access required for OpenAI API and NVIDIA NIM
- Local Deployment: Fully offline operation available with Ollama setup
- Hybrid Support: Mix cloud and local LLMs based on your requirements
- Analysis Time: 2-8 minutes per file (improved from original 5-10 minutes)
- Concurrent Processing: Multiple file analysis supported
- Resource Requirements: 8GB RAM minimum, 4+ CPU cores recommended
- Rate Limiting: Built-in API rate limiting and retry mechanisms
- AI QA Review: Automated false positive detection reduces manual validation
- Enhanced Accuracy: Modern LLM models provide better vulnerability detection
- Duplicate Detection: Intelligent finding deduplication (resolved from POC limitations)
- Confidence Scoring: AI-powered confidence levels for each finding
- API Key Security: Environment-based configuration, no keys committed to repository
- Local Processing: Complete on-premises deployment option with Ollama
- Data Privacy: No external data transmission when using local LLM providers
- Audit Trail: Comprehensive logging for security compliance
If upgrading from AIQ Toolkit version:
-
Backup Current Setup:
docker compose down cp .env .env.backup
-
Update Repository:
git pull origin main
-
Run New Setup:
./00-setup_nemo_agent_toolkit.sh
-
Update Environment:
cp .env_example .env # Configure your preferred LLM provider -
Start New Services:
./start_open-code-review.sh ./run_migrations.sh
- Function Calling Models: Not all local models support required function calling
- Large File Processing: Files >10MB may require chunking for optimal analysis
- API Rate Limits: Cloud providers have usage limits (see troubleshooting section)
OpenCodeReview has undergone a complete migration from the deprecated AIQ Toolkit to the modern NVIDIA NeMo Agent Toolkit (NAT), delivering significant improvements in performance, reliability, and functionality.
- Enhanced Architecture: Modern agent-based framework with improved error handling
- Better Performance: Optimized AI orchestration and execution pipeline
- Multi-Provider Flexibility: Seamless switching between OpenAI, NVIDIA, and local Ollama
- Function Calling Support: Proper tool integration for advanced AI capabilities
- Local LLM Compatibility: Improved support for on-premises AI deployment
- Future-Proof Design: Built on NVIDIA's latest agent toolkit technology
- New Service Architecture:
nvidia-natservice replaces deprecatedaiqtoolkitservice - Enhanced Configuration: Dynamic LLM provider selection with environment variables
- Improved API Integration: New
natClient.tswith better error handling and timeouts - Docker Optimization: Streamlined container builds and deployment process
- Database Schema Updates: Enhanced finding management with QA review capabilities
Critical for Local Models: Not all local models support function calling (tool usage) required by NAT.
Recommended Configurations:
- ✅ OpenAI:
gpt-4o-mini,gpt-4o(Full function calling support) - ✅ NVIDIA:
meta/llama-3.1-8b-instruct(Function calling supported) ⚠️ Ollama: Model-dependent (many models likegemma3:4bdo not support function calling)
Existing OpenCodeReview installations will continue to work, but users are encouraged to update:
- New Setup Script: Use
./00-setup_nemo_agent_toolkit.shinstead of the old AIQ setup - Environment Configuration: Update
.envfile with new NAT-compatible settings - Model Compatibility: Verify your chosen LLM model supports function calling
- Service References: All backend services now use the enhanced NAT integration
- Faster Analysis: Optimized AI workflow reduces analysis time
- Better Reliability: Enhanced error handling and recovery mechanisms
- Real-time Updates: Improved WebSocket integration for live progress tracking
- Memory Efficiency: Optimized container resource usage
- API Key Management: Improved environment variable handling and validation
- Container Isolation: Better Docker network security and service isolation
- Error Logging: Enhanced debugging capabilities while protecting sensitive data
OpenCodeReview now supports Local LLM deployment through Ollama integration, enabling you to run AI code analysis entirely on your own infrastructure without external API dependencies.
Key Benefits:
- Complete Privacy: No data leaves your network
- Cost Control: No per-token API charges
- Custom Models: Use any Ollama-supported model
- Offline Operation: Works without internet connectivity
Supported LLM Providers:
- OpenAI: Cloud-based GPT models (gpt-4o, gpt-4o-mini)
- NVIDIA: NIM models via NVIDIA's API (meta/llama-3.1-8b-instruct)
- Ollama: Local models (gemma3:4b, llama3.1, codellama, etc.)
Configuration Example:
# Local Ollama Setup
LLM_PROVIDER=ollama
OLLAMA_URL=http://192.168.1.100
OLLAMA_PORT=11434
OLLAMA_MODEL=gemma3:4b
OLLAMA_API_KEY=EMPTYNew AI QA Review functionality that uses AI as a Senior IT Security Consultant to perform quality assurance on security findings, significantly reducing false positives.
AI QA Review Features:
- Automated False Positive Detection: AI analyzes findings against actual source code
- Expert-Level Analysis: Uses security consultant-level prompts and reasoning
- Status Validation: Automatically updates finding status (confirmed, false_positive, needs_review)
- Detailed Reasoning: Stores AI's analysis and reasoning for each review
- One-Click Review: Simple button in FindingDetail page with real-time processing
QA Review Process:
- AI examines the security finding details
- Compares against actual source code context
- Provides confidence assessment (high/medium/low)
- Delivers professional recommendation with detailed analysis
- Updates finding status and stores reasoning
Enhanced code analysis workflow with Selective Review capability, allowing users to choose specific security review types instead of running comprehensive analysis.
Review Options:
- Comprehensive Review: All OWASP 2021 Top 10 categories (default)
- Selective Review: User-defined review types for targeted analysis
Selective Review Benefits:
- Faster Analysis: Focus on specific vulnerability categories
- Resource Efficiency: Reduced computation time and API costs
- Targeted Assessment: Choose relevant security categories for your context
- Flexible Workflow: Mix and match review types as needed
Available Review Categories:
- A01:2021 – Broken Access Control
- A02:2021 – Cryptographic Failures
- A03:2021 – Injection
- A04:2021 – Insecure Design
- A05:2021 – Security Misconfiguration
- A06:2021 – Vulnerable and Outdated Components
- A07:2021 – Identification and Authentication Failures
- A08:2021 – Software and Data Integrity Failures
- A09:2021 – Security Logging and Monitoring Failures
- A10:2021 – Server-Side Request Forgery (SSRF)
- General Security Review
- Real-time Progress Tracking: Live updates during AI analysis
- Improved Error Handling: Better feedback and recovery mechanisms
- Enhanced WebSocket Integration: Reliable real-time communication
- Streamlined UI/UX: More intuitive workflow for code review process
- Multi-Provider LLM Architecture: Flexible executor pattern for different AI providers
- Database Schema Enhancements: Added QA review fields and improved finding management
- Enhanced Logging: Comprehensive analysis tracking and debugging capabilities
- Rate Limiting Optimization: Improved API request management and performance